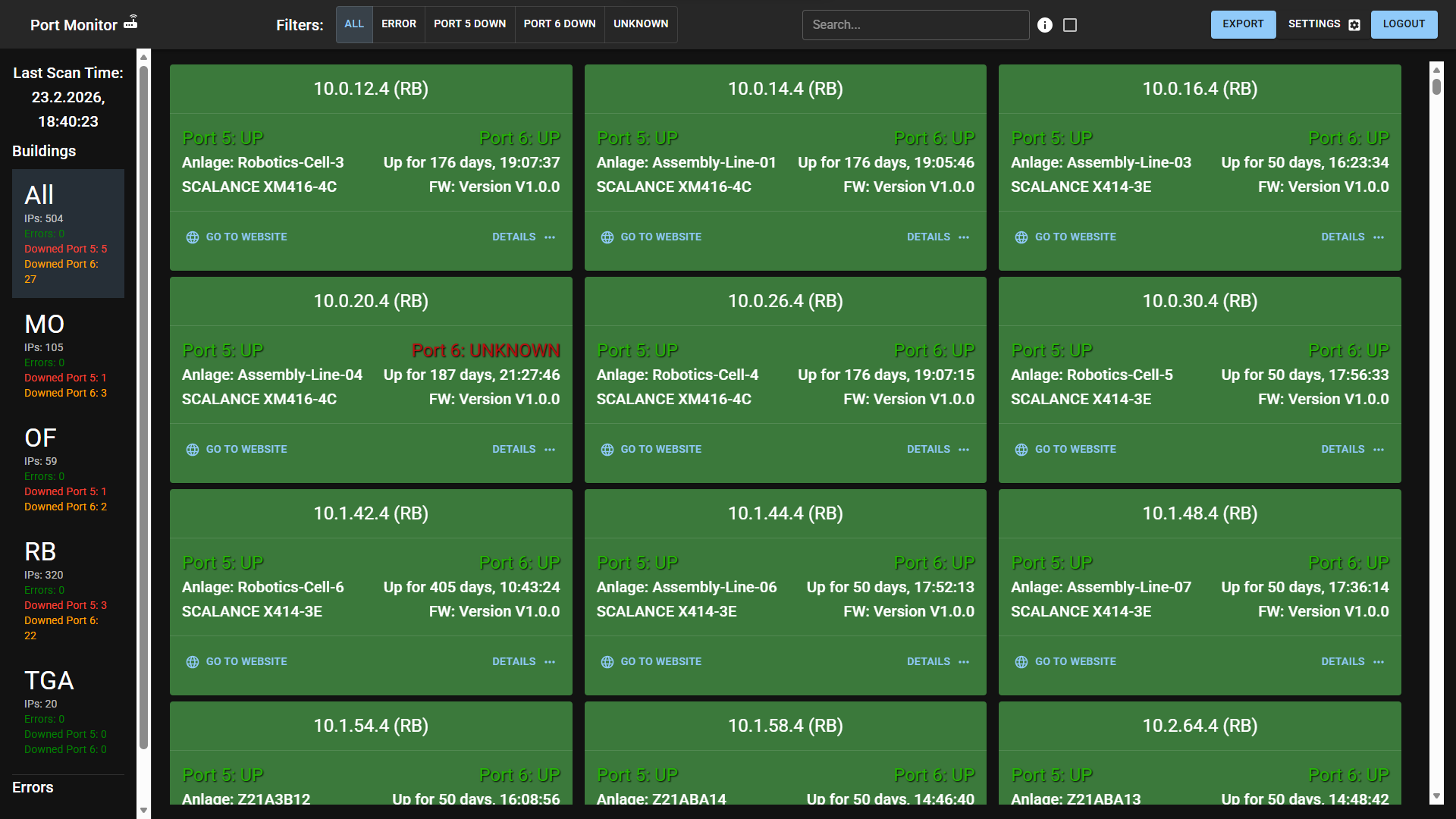
Industrial Redundancy Monitor is a custom monitoring system for production networks with redundant uplinks. It detects the “silent failure” condition where one uplink is already down, but failover masks the issue until a second failure can cause plant-wide downtime.
My Role
I designed and implemented this project end-to-end myself:
- Backend: High-concurrency Python service using AsyncIO for non-blocking SNMP polling.
- REST API: Design and security implementation (JWT-protected endpoints).
- Frontend dashboard: Architecture and performance optimization.
- Infrastructure: Deployment on Windows Server with IIS reverse proxy.
Problem: Silent Redundancy Failure
In industrial environments, switches commonly use redundant uplinks (e.g., RSTP/MRP). If the primary link fails, traffic automatically moves to the backup.
- Issue: The network still appears healthy, so the first failure often goes unnoticed.
- Consequence: The system now runs with no redundancy and a single remaining point of failure.
- Gap: No centralized visibility existed for per-port uplink health.
Key Features
- Zero-config auto-discovery: Parses PLC backup filenames to discover active switches and metadata.
- Intelligent uplink detection: Uses hardware-specific logic (SFP diagnostics for modern devices) and status inference for legacy models.
- Consolidated alerting: Aggregates scan-cycle failures into one report to reduce alert fatigue.
- Historical tracking: Stores failure counts and outage duration in SQLite for trend analysis.
- Secure API: JWT-protected endpoints for frontend access.
Architecture
The scanner is decoupled from the web UI so monitoring remains stable under frontend load. To ensure 24/7 reliability, the scheduler executes the monitoring engine as an isolated subprocess. If a scan hangs or crashes due to network issues, it does not impact the API server availability.
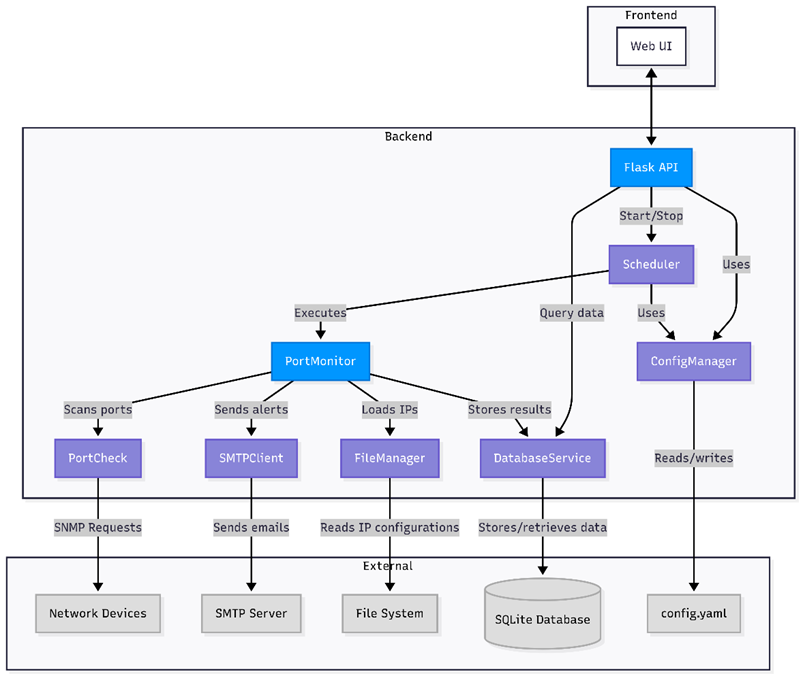 Figure 1: Component-level architecture used in implementation (service boundaries and external dependencies).
Figure 1: Component-level architecture used in implementation (service boundaries and external dependencies).
Scan Cycle Flow
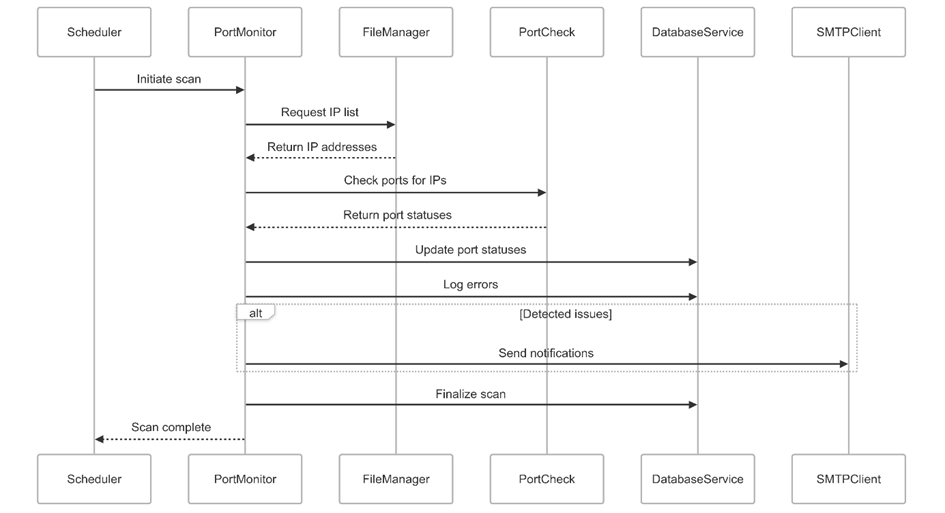 Figure 2: Runtime scan flow from scheduler trigger to persistence and conditional notifications.
Figure 2: Runtime scan flow from scheduler trigger to persistence and conditional notifications.
Deep Dive: Engineering Challenges
1) Adaptive Polling Strategy (Polymorphism)
Challenge: The network contained a mix of modern and legacy switches with different SNMP capabilities.
Solution: I implemented a polymorphic scanning engine. The system first retrieves the device model (e.g., SCALANCE X308-2M vs X414-3E) and dynamically selects the correct parsing strategy at runtime. This allows modern diagnostics (fiber power levels, temperature) to coexist with basic legacy status checks in a single unified codebase.
2) Auto-Discovery and Deduplication
Challenge: Maintaining 500+ switch IPs manually is error-prone.
Solution: The monitor scans PLC backup directories and parses filenames such as Plant_A@10.168.1.20#Slot1.plcconfig. A deduplication step ensures each switch is polled exactly once per cycle.
3) Frontend Performance for 500+ Devices
Challenge: Rendering all status cards caused DOM lag on older maintenance PCs.
Solution: I implemented list virtualization with react-window, rendering only visible elements plus a small buffer.
4) Enterprise Deployment (IIS + SSL)
Challenge: Corporate policy required HTTPS, but Flask/Waitress served HTTP.
Solution: IIS terminates SSL, serves frontend assets, and reverse-proxies /api/* to the backend process. This avoids mixed-content issues while keeping the Python service unchanged.
Quantitative Metrics
| Metric | Value | Notes |
|---|---|---|
| Managed switch inventory | 500+ devices | Based on production target scope |
| Scan efficiency | ~30% reduction | Duplicate IPs removed via analyzing PLC config overlaps |
| Concurrency model | Non-blocking AsyncIO | Parallel SNMP walking for rapid cycle completion |
| Alert aggregation | 1 consolidated report | Replaces individual emails per failed device |
Tech Stack
| Domain | Technologies |
|---|---|
| Backend | Python, AsyncIO, Flask, Waitress, APScheduler |
| Data Layer | SQLAlchemy, SQLite |
| Protocol | PySNMP (Async/Await), SNMPv2c |
| Frontend | React, Redux Toolkit, Material UI, react-window |
| Infrastructure | Windows Server, IIS (Reverse Proxy) |
Key Code Snippet
To minimize scan time across 500+ devices, I implemented a fully asynchronous SNMP client using pysnmp’s modern v3arch asyncio engine. This approach allows the backend to poll devices in parallel without blocking the event loop.
from pysnmp.hlapi.v3arch.asyncio import *
class PortCheck:
async def snmp_walk(self, host, oid, community='public', port=161):
"""
Perform an asynchronous SNMP walk to retrieve subtree data.
Uses pysnmp's asyncio engine to prevent blocking the main thread.
"""
results = []
try:
target_oid = ObjectIdentity(oid)
# Use PySNMP's async iterator for non-blocking I/O
iterator = await walkCmd(
SnmpEngine(),
CommunityData(community),
UdpTransportTarget((host, port), timeout=self.timeout, retries=self.retries),
ContextData(),
target_oid
)
for errorIndication, errorStatus, errorIndex, varBinds in iterator:
if errorIndication:
# Log but allow partial failures for robustness
continue
elif errorStatus:
continue
else:
for varBind in varBinds:
results.append(varBind)
return results
except Exception as e:
# Propagate critical connection errors to the upper layer
raise ConnectionError(f"SNMP Walk failed for {host}: {str(e)}")Results and Retrospective
- Operational impact: During commissioning, the monitor surfaced multiple
UNKNOWNuplink states. On-site checks traced these to installation issues (fiber connected, but missing SFP transceivers). - Validation: Requirement-linked black-box tests confirmed detection, recovery, consolidation, and API behavior under tested conditions.
- Current limitation: SNMPv2c is used for compatibility with legacy hardware.
- Next step: Migrate toward SNMPv3 (where hardware permits) for stronger authentication and encryption.
Validation Strategy
To ensure reliability in a production environment, I conducted formal black-box testing on a physical testbench (Windows Server + IIS + Switch Topology).
- Link Failure & Recovery: Simulating physical cable pulls (
UP -> DOWN -> UP) to verify the system detects the break within 1 scan cycle and clears the error upon reconnection. - Legacy Hardware Compatibility: Verifying that older switches (X308) logic correctly maps port status despite missing SNMP OIDs found in newer models.
- Alert Deduplication: Triggering simultaneous failures to confirm the system aggregates them into a single notification, preventing “alert storms.”
- Security Penetration: Attempting unauthorized API access with invalid/expired JWTs to verify 401/403 rejections.
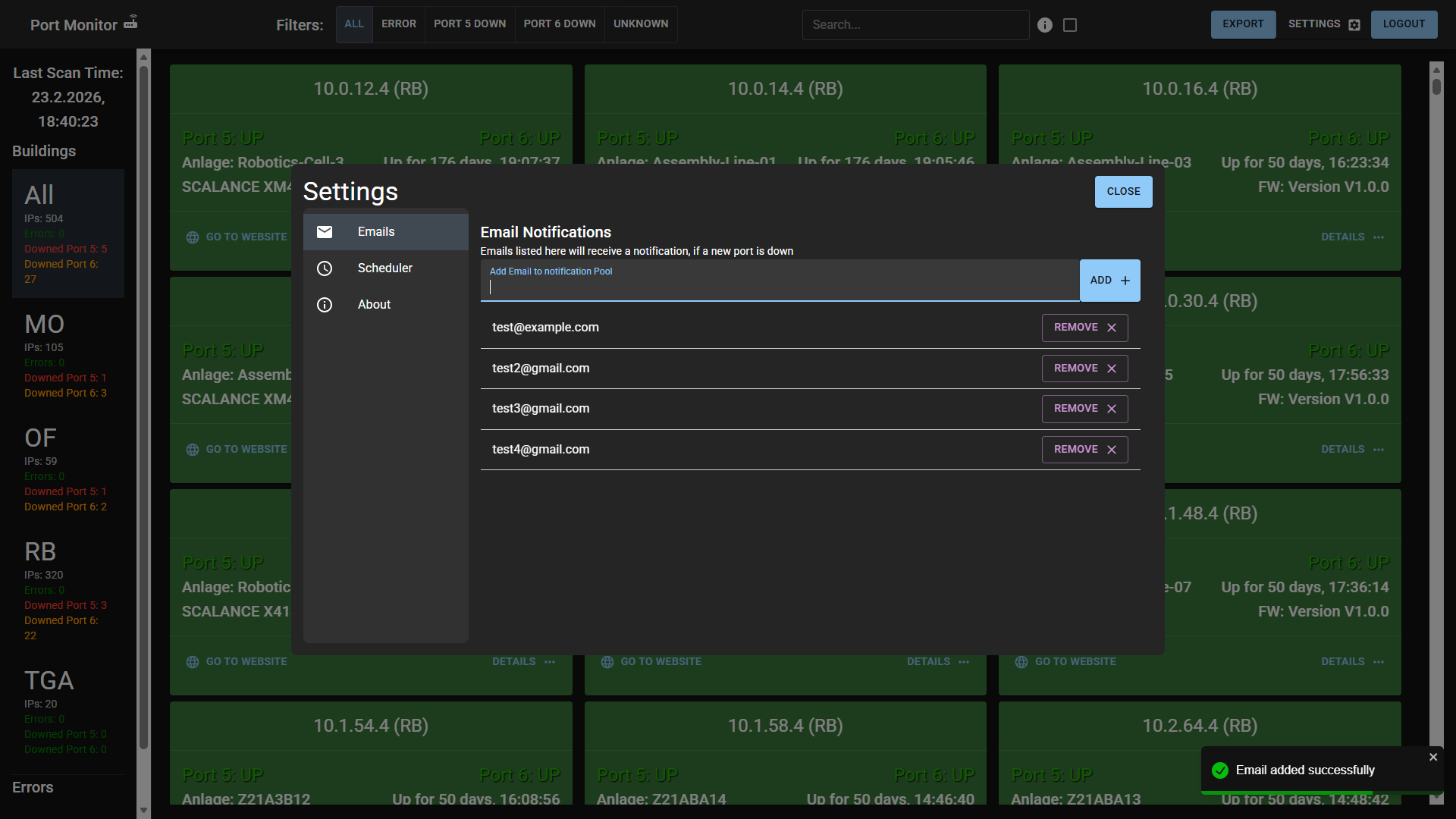 Figure 3: Administrative settings view used for notification recipient management and scheduler operations validated in system tests.
Figure 3: Administrative settings view used for notification recipient management and scheduler operations validated in system tests.
Trade-offs
SNMPv2c was retained because installed legacy switch models and existing plant conventions prioritized compatibility and low rollout risk. The trade-off is weaker protocol-level security (no authentication/encryption), plus manual effort for legacy port-index handling. Current mitigations are segmented network placement, HTTPS + JWT on the application layer, restricted server access, and consolidated monitoring logs for anomaly review.
Lessons Learned
The main engineering takeaway is that availability gains in brownfield industrial networks depend less on algorithmic novelty and more on robust integration choices: compatibility-first protocol selection, deterministic scheduling, clear failure classification, and operationally usable visualization. Structuring discovery, polling, persistence, and presentation as separate modules improved testability and reduced deployment risk.